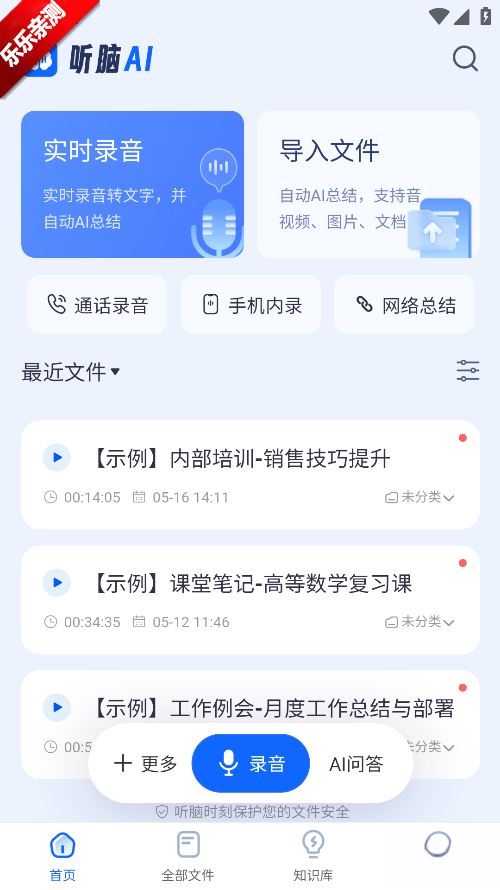



听脑AI是依托前沿人工智能技术构建的智能语音处理平台,专注于为用户提供高效精准的语音转文字服务以及覆盖全场景的信息管理解决方案,具备音视频解析、网络内容提取和思维导图生成等功能,帮助用户快速提炼核心信息。平台严格遵循国密级数据加密标准,是实现智能化办公与学习的得力助手。
打开听脑AI,点击录音。

输入手机号码和验证码进行注册登录。

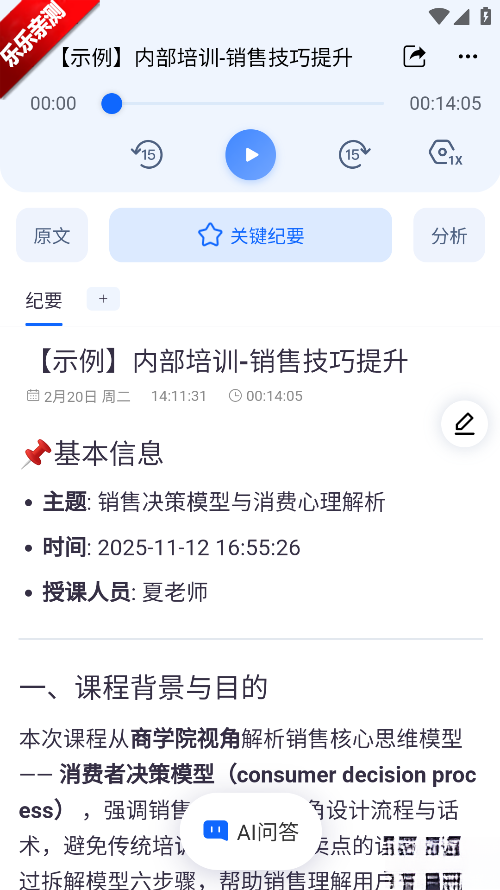
点击ai问答。

在下方输入所选的范围的提问内容。

听脑AI作为依托人工智能技术研发的智能语音处理工具,专注于为用户带来高效且精准的语音转文字体验,同时深度融合了智能总结、多语言适配、场景化记录等多元功能,广泛满足职场会议、教育学习、内容创作、销售客服等不同领域的使用需求。它的核心优势在于借助自动化技术让用户摆脱手动操作的繁琐,有效提升信息处理的效率,并且在数据安全防护与跨平台协同方面提供可靠保障。该软件运用语义分析技术,能够自动提炼语音里的关键内容,生成包含标题、分点、重点标注的会议纪要,还会清晰标记时间节点、任务分配以及截止日期;此外,它可以识别语音中的行动指令(例如“下周三前提交方案”),自动生成待办事项清单,大幅降低人工整理所需的时间成本。听脑AI还提供会议、课程、采访、灵感记录等预设使用模式,针对不同场景对识别策略进行优化调整,支持手机、电脑、平板等多设备实时同步,团队用户能够共享会议记录并进行协同编辑,通过权限分级管理确保信息流转既安全又高效。
选择录音方式
实时录音操作步骤:启动听脑AI应用后,在主界面找到并点击“录音”按钮,即可进入录音界面。
上传音频或视频:要是你已经有了方言录音文件,像m4a、mp3这类格式的,就能直接把它上传到平台上,平台支持从本地文件导入,也支持通过网络链接导入。
路径一:在录音界面或者上传设置里,找到“语言/方言”这个选项,从20多种主流方言(像四川话、粤语、东北话、闽南语之类的)中挑选对应的类型。要是不确定具体的分支,就可以开启“方言自适应”模式,系统会自动匹配最相近的方言类型。
路径二:可先在“设置”菜单里预先设置好方言类型,这样之后进行录音或上传操作时,系统就会自动启用该方言设置。
降噪处理:采用双麦克风阵列降噪技术,主麦克风负责拾取人声,副麦克风专门捕捉环境噪音,通过智能算法过滤掉背景中的干扰声音(例如空调运行声、人员脚步声等),从而有效提高语音转写的清晰度。
动态增益调节:可自动适配说话人音量的变化(比如轻声说话或音量骤升),对收音灵敏度进行智能调整,从而防止出现声音微弱或破音的情况。

实时录音:点击主界面“实时录音”按钮,允许麦克风权限后即可开始录音,录音过程中可随时暂停、继续。
上传文件的操作步骤如下:首先点击“上传记录”选项,接着可以选择本地存储的音频或视频文件(支持MP3、WAV、MP4等常见格式),也能够直接粘贴网络上的音视频链接(例如B站、YouTube等平台的视频链接)。
语言/方言的选择方式如下:在进行录音或者上传操作的设置界面里,挑选相应的语言(比如中文、英文)或者方言(例如四川话、粤语)。要是对具体的方言类型不太确定,那么可以开启“方言自适应”功能模式。
场景选择:依据录音内容挑选对应的场景类别(像会议、医疗、教育这类),系统就会对识别逻辑进行优化,从而提高识别的准确率。举例来说,要是选择了“医疗健康”这个场景,系统就能优先识别医疗相关的专业术语。
点击“开始转写”按钮,随后静候系统完成处理流程(一般情况下,时长为10分钟的录音,系统处理大约需要1到2分钟)。
转写结束后,可在记录详情页面查看原文转写结果、AI生成的总结纪要以及提取出的关键词等信息,同时还能对这些内容进行编辑、导出或分享操作。
下载排行





 Acfan鼻血版1.3.9
Acfan鼻血版1.3.9 蘑菇短视频隐藏路线官网版
蘑菇短视频隐藏路线官网版 今日抽烟
今日抽烟 修修漫画免费漫画
修修漫画免费漫画 得物(毒)
得物(毒) 运动赚钱
运动赚钱 papago官网版2025
papago官网版2025 开市客
开市客 FZ辅助平台
FZ辅助平台 原味二手货
原味二手货









