
Gemini是由先进人工智能技术驱动的智能交互工具,融合了强大的语言推理能力与多模态生成技术。这款人工智能模型不仅拥有出色的信息分析与逻辑识别能力,还能在商业预测、数据研判、内容创作等多种复杂场景中灵活应对。谷歌AI Gemini可以根据用户提供的文本内容,生成契合语境的视频或图像,显著提升创意表达的效率。此外,Gemini还引入了新一代视频生成模型Veo3,进一步拓展了从图文到视频的转换能力,适用于内容营销、教育培训、媒体制作等多个领域。
温馨提示:在启动gemini之前,需要先安装谷歌三件套,这样才能正常使用。
1、文本使用
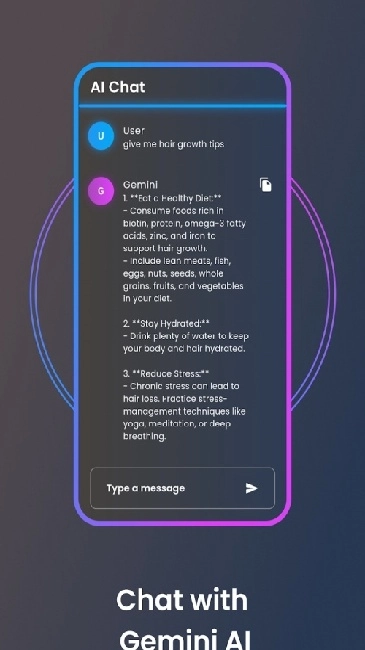
用户能够在交互界面的输入栏中直接输入问题、指令或者任务说明,比如粘贴一篇论文并附上“提炼核心观点”的要求,又或者提供完整设定让模型创作科幻小说,描述要尽量清晰、具体,这样可以提高模型响应的精准度。
2、图片或音频分析
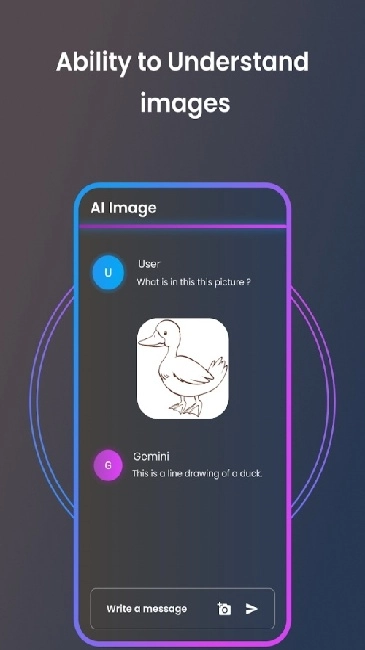
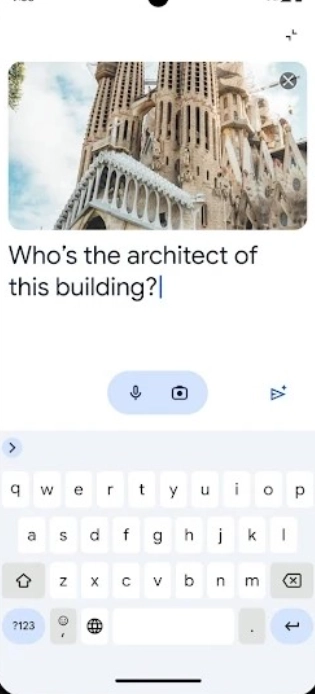
可以点击界面上的上传图标,选择本地的相关文件。上传图片后能够补充说明,比如“请解析图中人物的动作”;上传音频后可以提出要求,例如“分析语调与情绪变化”。多模态能力支持图文、音音之间的协同处理。
3、获取结果
提交请求后,系统会在短时间内生成响应内容,输出形式可能有文字总结、代码、分析数据等。要是初次结果没达到预期,用户可以适当修改输入内容或者补充上下文,不断优化指令,直到得到理想的答案。
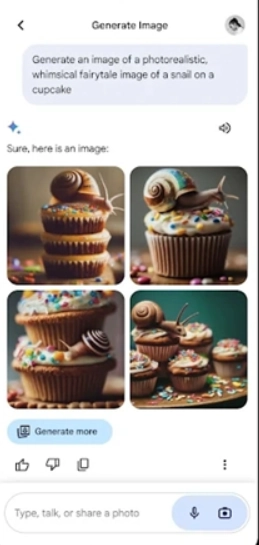
1、支持文字、图片、音频等多种输入形式,可同时对这些内容进行理解,互动方式更为灵活。
2、在复杂领域中展现出稳定的表现,能够协助用户分析文献、阐释知识点,非常适合用于进行深入学习。
3、拥有文本优化的能力,能够增强内容的表达效果,不管是写作工作还是编辑工作都可以胜任。
4、会依据使用情况持续优化回答的风格与内容,给出更契合用户习惯的建议。
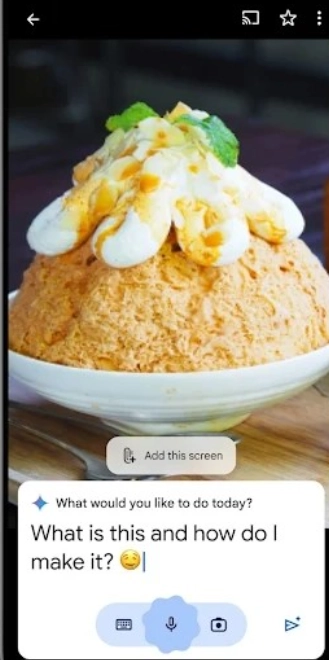
1、能够生成多种编程语言的代码,并且可以帮助修复和优化程序。
2、具备长文本创作与修改功能,可满足论文撰写、故事创作或内容策划等场景需求。
3、学术分析能力突出,可协助解读复杂文献并提供研究方向建议。
4、融合多模态输入方式,可识别并处理图像、文字与语音信息,以适配更丰富的应用场景。
1、操作便捷却功能完备,无论是学习、工作还是创作,都能找到适配的使用方式。
2、在保障性能的同时注重安全,隐私保护机制完备,让使用更放心。
3、可提供持续优化升级的服务体验,互动对话越频繁,反馈结果就越精准。
4、作为谷歌开发的AI,系统稳定可靠,品质有保障。
下载排行





 今日抽烟
今日抽烟 修修漫画免费漫画
修修漫画免费漫画 papago官网版2025
papago官网版2025 开市客
开市客 FZ辅助平台
FZ辅助平台 原味二手货
原味二手货


