
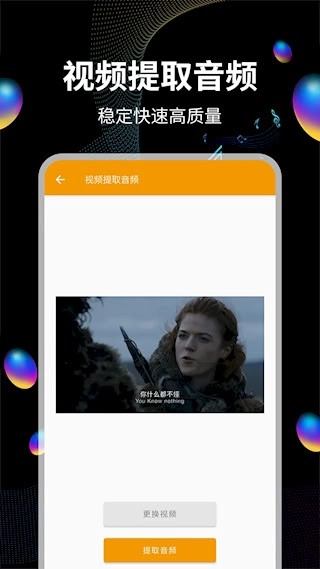
音频提取运用智能分离技术,可高效实现人声与背景音乐的分离,能从各类多媒体文件中提取出纯净音频,支持从视频文件、在线流媒体等多种渠道分离音轨,且能保留原始音质。此外还具备批量处理功能,可同时转换多个文件。有需求的小伙伴可以点击操作。
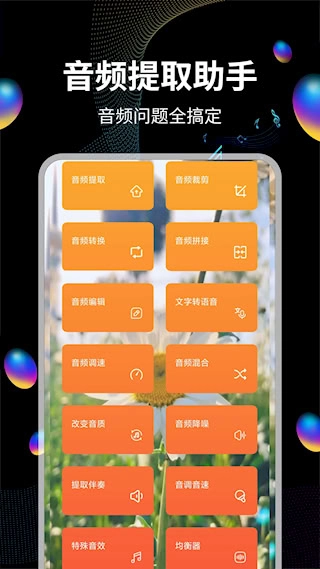
1、支持从视频素材里提取出纯净的音轨,把影像内容转换成独立的音频文件进行保存
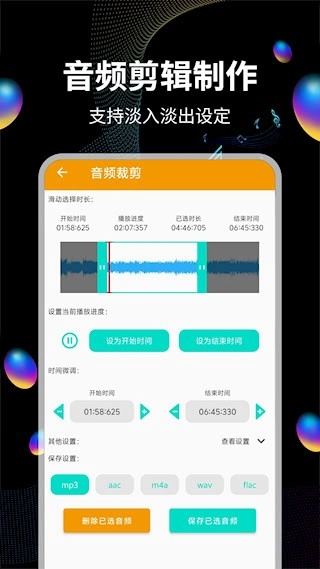
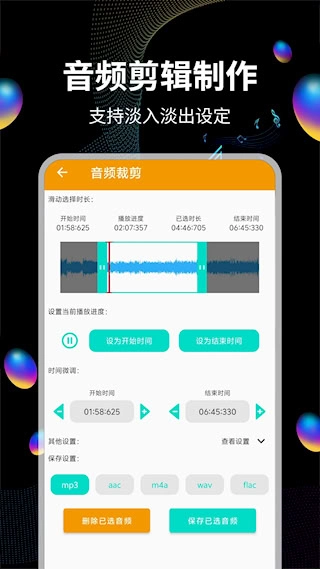
2、具备精准的音频裁剪功能,支持自由设定截取范围以生成新文件,适用于铃声制作等场景
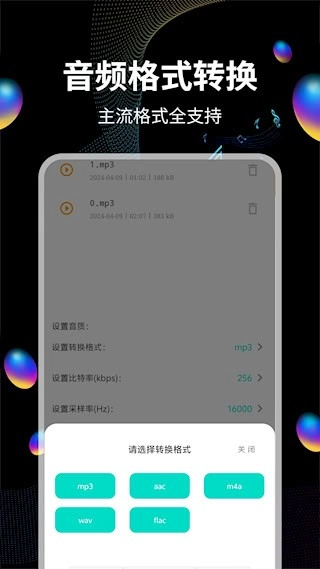
3、拥有多格式转换功能,可实现MP3/FLAC/AAC等主流音频格式的相互转换,能够满足用户多样化的播放需求。
4、配备多文件合并工具,能够把多个音频片段无缝拼接成完整的MP3格式文件
5、具备多轨道混合能力,允许同时播放多条音轨,且可对每条音轨的音量占比进行独立调整
6、变声效果器,配备多种预设音色可供选择,还支持对音调与播放速度进行独立调节
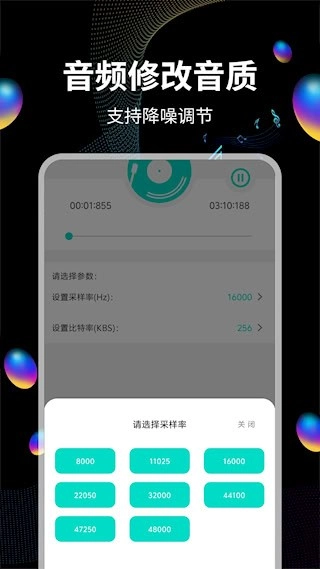
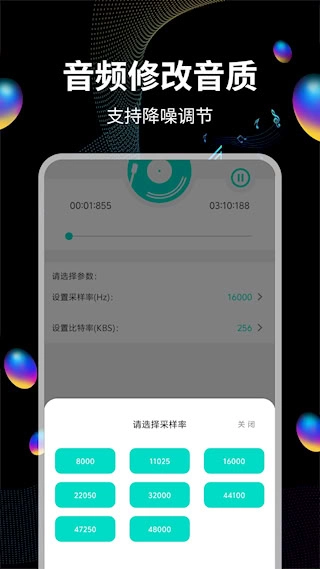
7、支持通过调整采样率和比特率参数来改变音频品质,从而实现文件大小与音质之间的平衡
8、搭载智能降噪算法,能有效压制环境噪音与电流杂音,增强音频纯净度
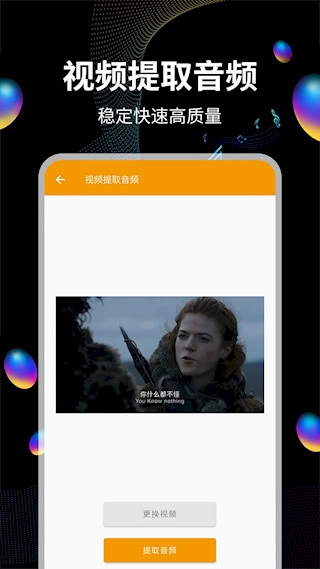
1、支持从视频文件里提取音频数据,能把MP4、MOV这类格式转换成MP3、WAV等音频格式。提取的时候能保持原始音质,最高可以支持320kbps的高质量输出。
2、拥有智能音频分割能力,借助波形分析自动识别静默段落。支持手动设定时间点以实现精准裁剪,能够删除指定片段或保留精华内容。
3、配备多格式转换引擎,可支持MP3、FLAC、AAC等12种格式之间的相互转换。在转换过程中,能够对采样率(范围为8k-192kHz)和比特率(范围为32-320kbps)的参数进行调整。
4、配备多文件合并工具,能够批量导入音频并实现无缝拼接。用户可自由调整交叉淡入淡出的时长,有效避免音频接合处出现爆音或停顿问题。
5、AI降噪算法借助深度学习技术精准识别环境噪音,能够高效滤除风扇运转声、键盘敲击声等常见噪声,同时确保人声的清晰质感。
1、相较于同类工具,处理速度提升了大约40%,提取3分钟视频的音频仅需10秒即可完成。支持后台批量处理功能,能够同时转换多个文件且不会出现卡顿现象。
2、界面设计荣获德国红点奖认可,核心功能在主界面均可一键直达。新手引导系统可让初学者在3分钟内掌握基本操作。
3、运用无损处理引擎,所有编辑操作都基于原始文件的备份来进行。配备256级撤销历史记录,能够支持任意步骤的回退操作。
4、音频算法由曾任职于杜比实验室的工程师参与开发,在音质保持方面表现出色。测试结果显示,同一文件历经10次格式转换后,音质损失仍不足2%。
5、已连续三年登上Google Play年度最佳工具类应用榜单,每月都会定期更新音效库与功能模块,不断优化用户的使用体验。
1、独家配备的“声纹保护”技术,可在降噪过程中智能识别并留存人声的独特特征。相关测试结果表明,这项技术让处理后的人声自然度较传统工具提高了60%。
2、支持云端协作编辑,能通过链接分享工程文件。团队成员可以同步开展音频处理工作,所有修改记录都会实时保存到云端。
3、智能响度均衡系统,能够自动对多段音频的音量水平进行分析。在合并文件的过程中,它会自动将响度统一,从而防止出现音量忽大忽小的情况。
4、具备“音频指纹”识别能力,能够对上传的音频进行版权信息检测。一旦识别出受保护的内容,系统会自动发出风险提示,从而防止侵权行为的发生。
5、支持对接主流音乐平台的曲库,只需输入歌名,就能智能匹配对应的伴奏。该功能的匹配准确率达到98%,大幅简化了音频素材的获取流程。
1、视频创作者反馈该工具的提取速度十分出色,处理4K视频音频的耗时仅为普通工具的一半。画质转换后,人声完整保留,背景音乐也没有出现失真情况。
2、多数评价表明降噪效果好于预期,在喧闹的咖啡厅录制的人声经过处理后清晰度有显著提升,智能识别功能还保留了说话时的口齿细节特征。
3、音乐教师群体对其批量处理功能尤为认可,借助该功能可一次性为多个班级的录制内容完成统一降噪处理,大幅减少了重复操作所耗费的时间。
4、专业音频工程师评价该格式转换质量可媲美专业设备,尤其是FLAC转MP3时的音质保留程度达到了商业软件的水平。
5、有部分使用者提议添加AI人声增强功能,不过大家普遍觉得当前的降噪与提取功能已经能够覆盖90%的日常使用场景了。
下载排行




 Acfan鼻血版1.3.9
Acfan鼻血版1.3.9 蘑菇短视频隐藏路线官网版
蘑菇短视频隐藏路线官网版 修修漫画免费漫画
修修漫画免费漫画 papago官网版2025
papago官网版2025 ph官方中文免费版
ph官方中文免费版 FZ辅助平台
FZ辅助平台










