
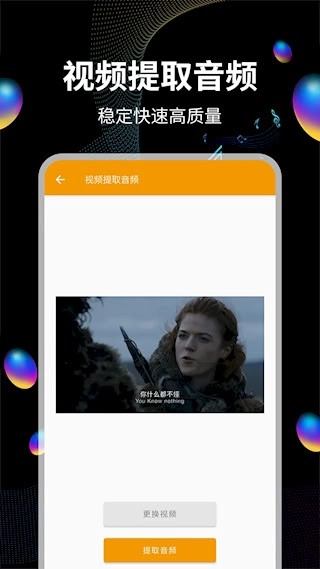
音频提取运用智能分离技术,可高效实现人声与背景音乐的分离,能从各类多媒体文件中提取出纯净音频,支持从视频文件、在线流媒体等多种渠道分离音轨,且能保留原始音质。此外还具备批量处理功能,可同时转换多个文件。有需求的朋友可以点击操作。
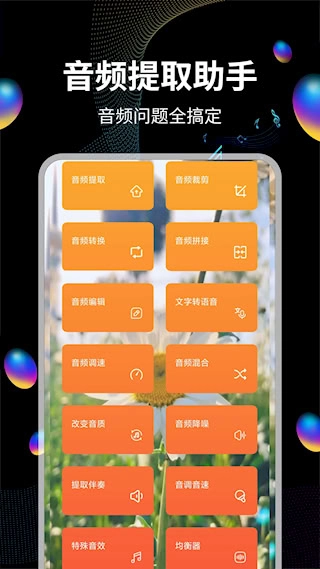
可以从视频素材里提取出纯净的音轨,把影像内容转换成独立的音频文件进行保存。
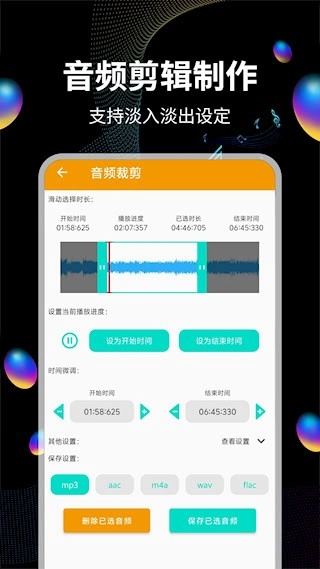
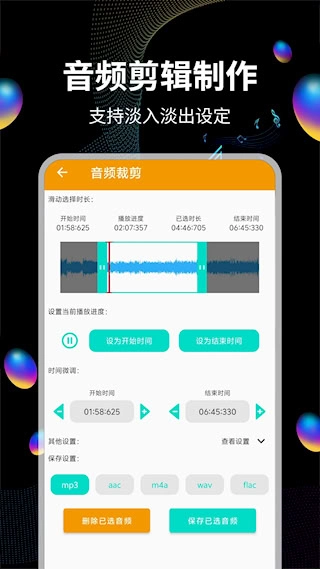
我们提供精准的音频裁剪功能,用户能够自由设定截取的时间区间,从而生成新的音频文件,这一功能非常适用于铃声制作等场景。
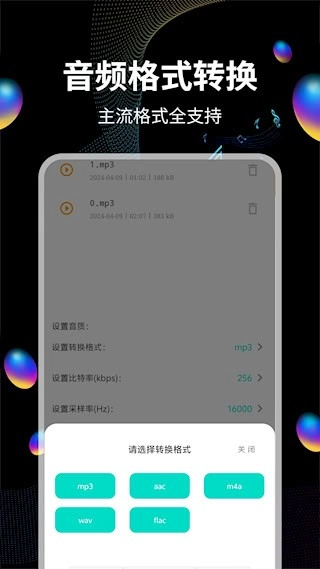
拥有多种格式转换的功能,可实现MP3、FLAC、AAC等常用格式之间的相互转换,能够满足不同场景下的播放需求
我们的工具具备多文件合并功能,能够把多个音频片段无缝拼接成完整的MP3格式文件。
具备多轨道混音能力,可同步播放多条音轨,且能对每条音轨的音量占比进行独立调控
变声效果器,多种预设音色可供挑选,还能分别对音调与播放速度进行调节。
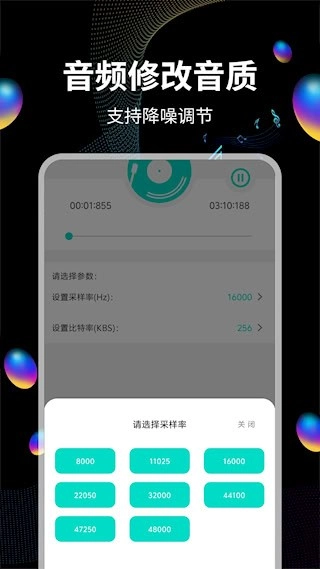
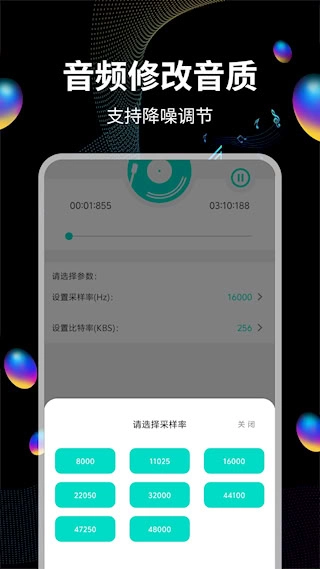
可以通过调整采样率和比特率参数来改变音频品质,从而在文件大小和音质之间找到平衡。
搭载智能降噪算法,能够有效过滤环境噪音和电流杂音,增强音频的纯净度
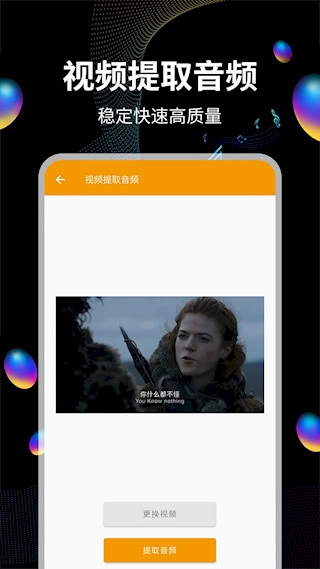
支持从视频文件中提取音频数据,能够把MP4、MOV等格式转换成MP3、WAV等音频格式。提取过程会保留原始音质,最高可支持320kbps的高质量输出。
拥有智能音频分割能力,借助波形分析能自动辨别静默段落。支持手动设定时间点来实现精准裁剪,既可以删除指定片段,也能保留精华内容。
我们配备了多格式转换引擎,能支持MP3、FLAC、AAC等12种音频格式之间的相互转换。在进行转换操作时,还可以对采样率(范围在8k到192kHz之间)以及比特率(范围为32到320kbps)这两项参数进行调整。
配备多文件合并工具,能批量导入音频并实现无缝拼接。还可调节交叉淡入淡出的时长,防止音频接合位置出现爆音或停顿问题。
AI降噪算法运用深度学习技术来辨别环境中的噪音,能够高效去除风扇运转声、键盘敲击声等日常常见噪声,同时确保人声的清晰程度不受影响。
处理速度比同类工具快约四成,提取3分钟视频的音频仅需10秒。支持后台批量操作,能同时转换多个文件且运行流畅不卡顿。
界面设计荣获德国红点奖认可,核心功能在主界面均可一键直达。新手引导系统可使初学者在3分钟内掌握基本操作。
采用无损处理引擎,所有编辑操作均基于原始文件的备份进行。配备256级撤销历史记录功能,可支持在任意操作步骤间回退。
音频算法有杜比实验室前工程师参与研发,在音质保持方面表现出色。测试结果显示,同一文件历经10次格式转换后,音质损失仍小于2%。
连续三年入选Google Play年度最佳工具类应用,每月都会定期更新音效库与功能模块,始终致力于优化用户的使用体验。
独有的“声纹保护”技术,可在降噪过程中智能识别并保留人声的独特特征。相关测试结果表明,这一技术能让人声自然度较传统工具提升60%。
支持云端协作编辑功能,能够借助链接分享工程文件。团队成员可以同步开展音频处理工作,所有的修改记录都会实时存储到云端。
智能响度均衡系统能够自动分析多段音频的音量水平,在合并文件时会自动将响度统一,从而避免音量忽大忽小的情况出现。
提供“音频指纹”识别服务,能够对上传的音频进行版权信息检测。一旦识别出受保护的内容,系统会自动发出风险提示,以此防止侵权行为的发生。
支持与主流音乐平台曲库进行对接,只需输入歌名,系统就能智能匹配对应的伴奏。该功能的匹配准确率达到98%,大幅简化了音频素材的获取步骤。
视频创作者反馈,这款工具的提取速度十分惊艳,处理4K视频音频的耗时仅为普通工具的一半。经过画质转换后,人声依然保持完整,背景音乐也没有出现失真的情况。
多数评价都觉得降噪效果比预想的要好,在嘈杂的咖啡厅里录下的人声,经过处理后清晰度有了显著提升。智能识别还保留了说话时的口齿细节特点。
音乐教师群体对其批量处理功能十分认可,借助该功能能够同时为多个班级的录制内容开展统一降噪工作,从而大幅减少了重复操作所耗费的时间。
专业音频工程师指出,该工具的格式转换质量已趋近专业设备水平,尤其是在FLAC转MP3这一常见转换场景中,音质的保留程度完全达到了商业软件的标准。
部分用户提议添加AI人声增强功能,不过大家普遍觉得目前的降噪与提取功能已经能覆盖90%的日常使用场景了。
下载排行




 Acfan鼻血版1.3.9
Acfan鼻血版1.3.9 修修漫画免费漫画
修修漫画免费漫画 得物(毒)
得物(毒) papago官网版2025
papago官网版2025 开市客
开市客 ph官方中文免费版
ph官方中文免费版









